Face aux silos historiques de données, aux difficultés rencontrées dans les exercices de centralisation des données et à la complexité résultante d’exploiter complètement le potentiel des données (“soyez data”), le Data Mesh définit la vision d’un cadre de vie des données dans l’entreprise. Cette vision a émergé des travaux de Zhamak Dehghani en 2019 (réf).
La vision proposée a l’intelligence de réunir dans un cadre cohérent, un ensemble de pratiques connues et éprouvées, qui vont permettre de fixer une vision et un chemin pour maîtriser, développer les données au sein d’une organisation (d’un domaine métier, d’une entreprise, jusqu’à un écosystème).
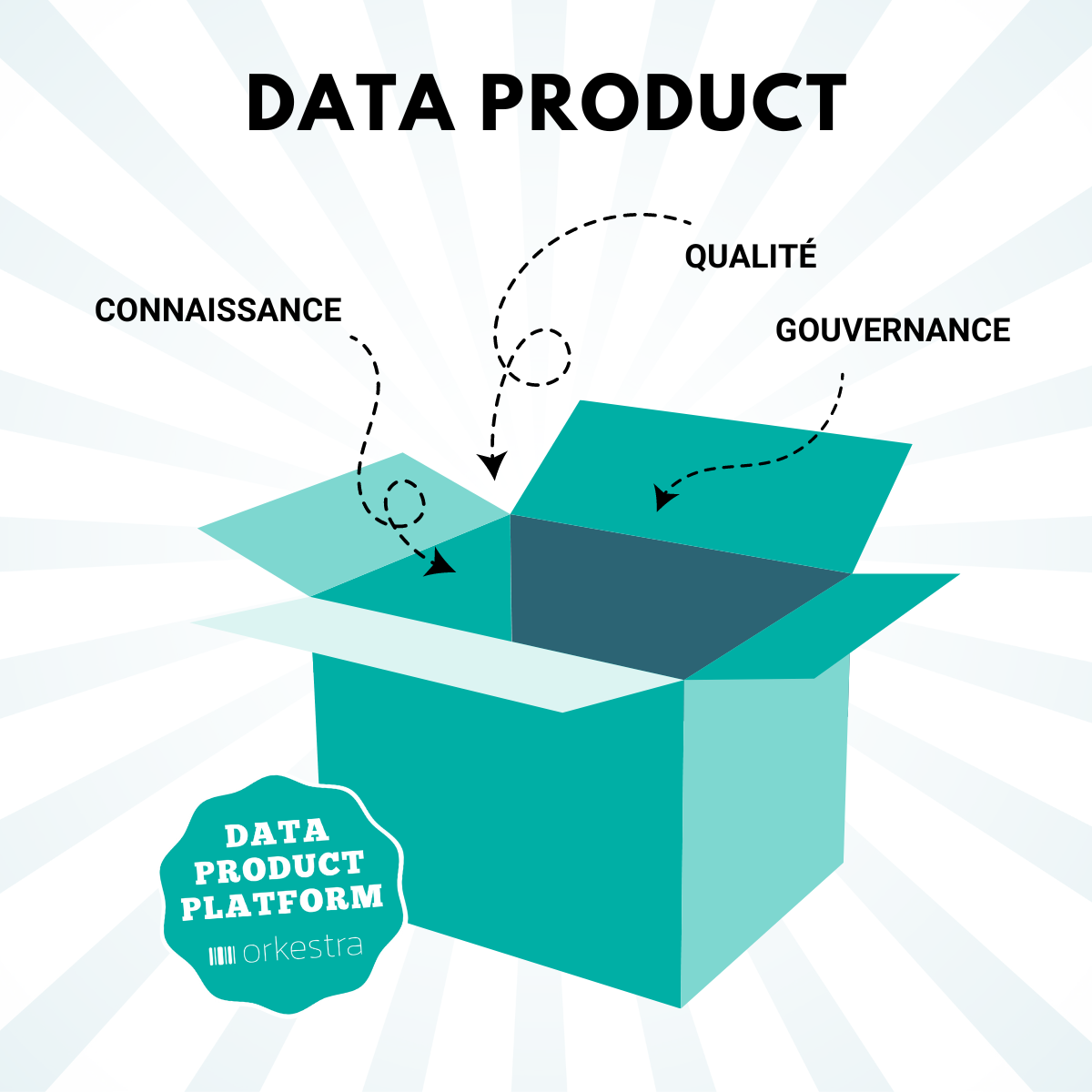
Ce cadre cohérent est composé de quatre piliers interdépendants. Les deux premiers piliers sont les données organisées sous forme de produit de données et sous la responsabilité de domaines métier. A cela, vient s’ajouter deux autres piliers : la définition de « self serve data platform » support à la définition, l’exploitation des produits de données et le principe de gouvernance fédérée permettant de s’assurer de la bonne maîtrise des produits de données et de la qualité du maillage, c’est-à-dire des liens entre données, à tous les niveaux de l’organisation.
Les 4 piliers du Data Mesh
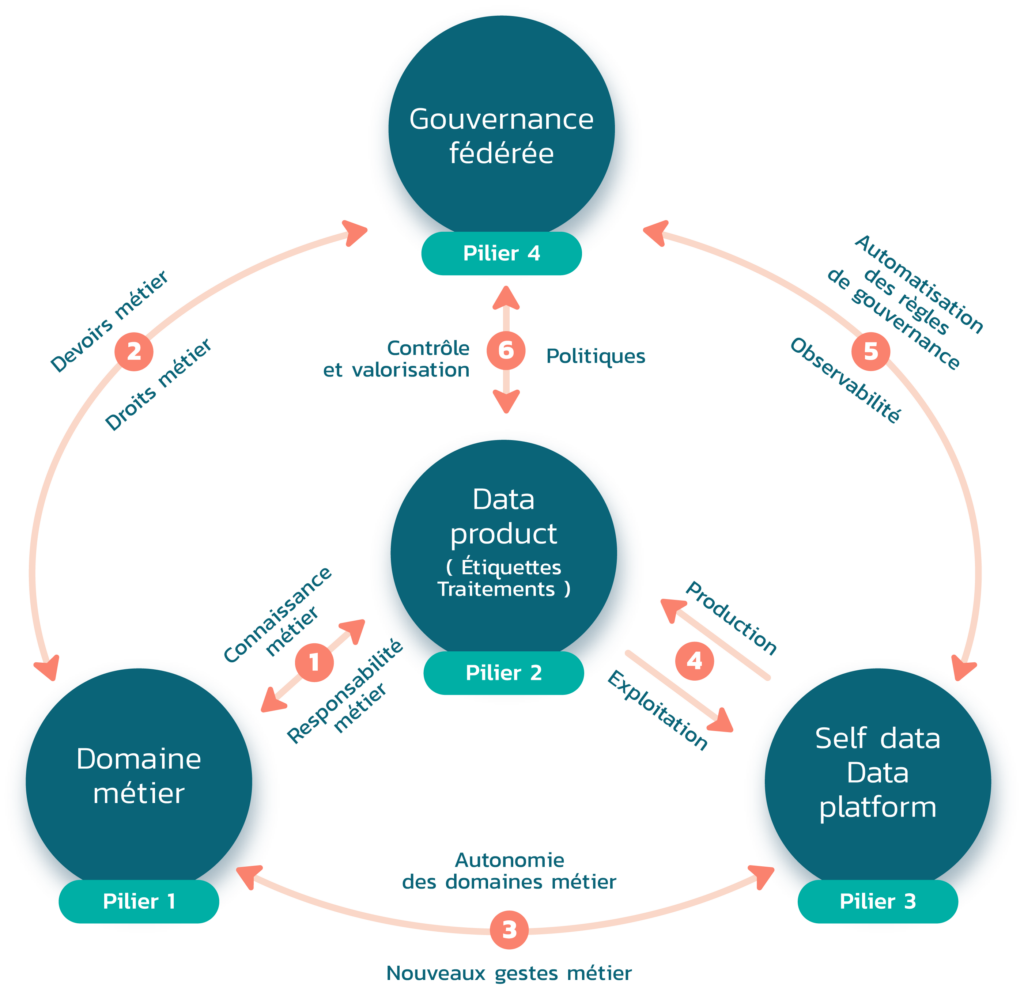
La promesse centrale du Data Mesh est d’offrir des moyens performants de traitement et d’utilisation des données tout en construisant un maillage de données cohérent, de qualité, sous gouvernance et à valeur.
Ce maillage de données est constitué de l’ensemble des produits de données et de leurs relations entre eux :
- Des relations structurelles de composition-construction : tel produit de données est construit à partir de tels autres produits de données (matérialisés par des pipelines de traitements de données), tel produit de données fait appel à telles données appartenant à tel modèle de données,
- Des relations fonctionnelles entre producteurs et consommateurs : tel produit de données est consommé par tel domaine métier et issu de tel domaine métier producteur (matérialisé dans les pipelines de données par des contrats de service entre producteur et consommateur).
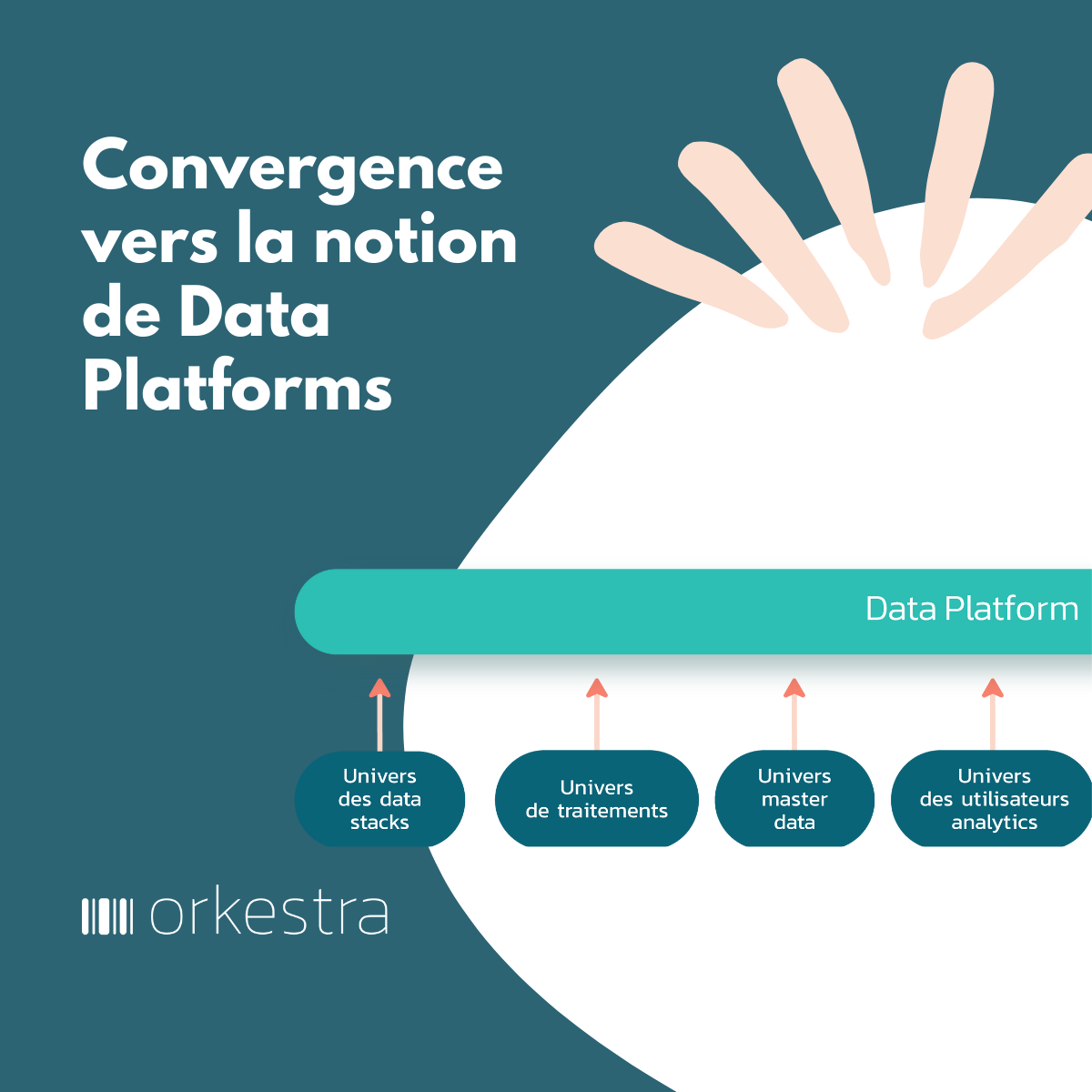
Le Data Mesh s’applique à tous les niveaux de l’entreprise. Sa force vient de l’enchâssement de ses principes et règles sur les données qui s’appliqueront suivant la portée de celles-ci, c’est-à-dire leur périmètre d’exercice :
- Des règles locales (définies par le domaine métier)
- Des règles interfonctionnelles (exemple dans le cadre d’un processus inter-domaines, d’un suivi de bout en bout, d’une vue 360°)
- Des règles globales d’entreprise : respect des référentiels, réglementaires, liées à des expertises transverses (juridique, sécurité, risques, compliance)
La vision portée par le Data Mesh est ambitieuse.
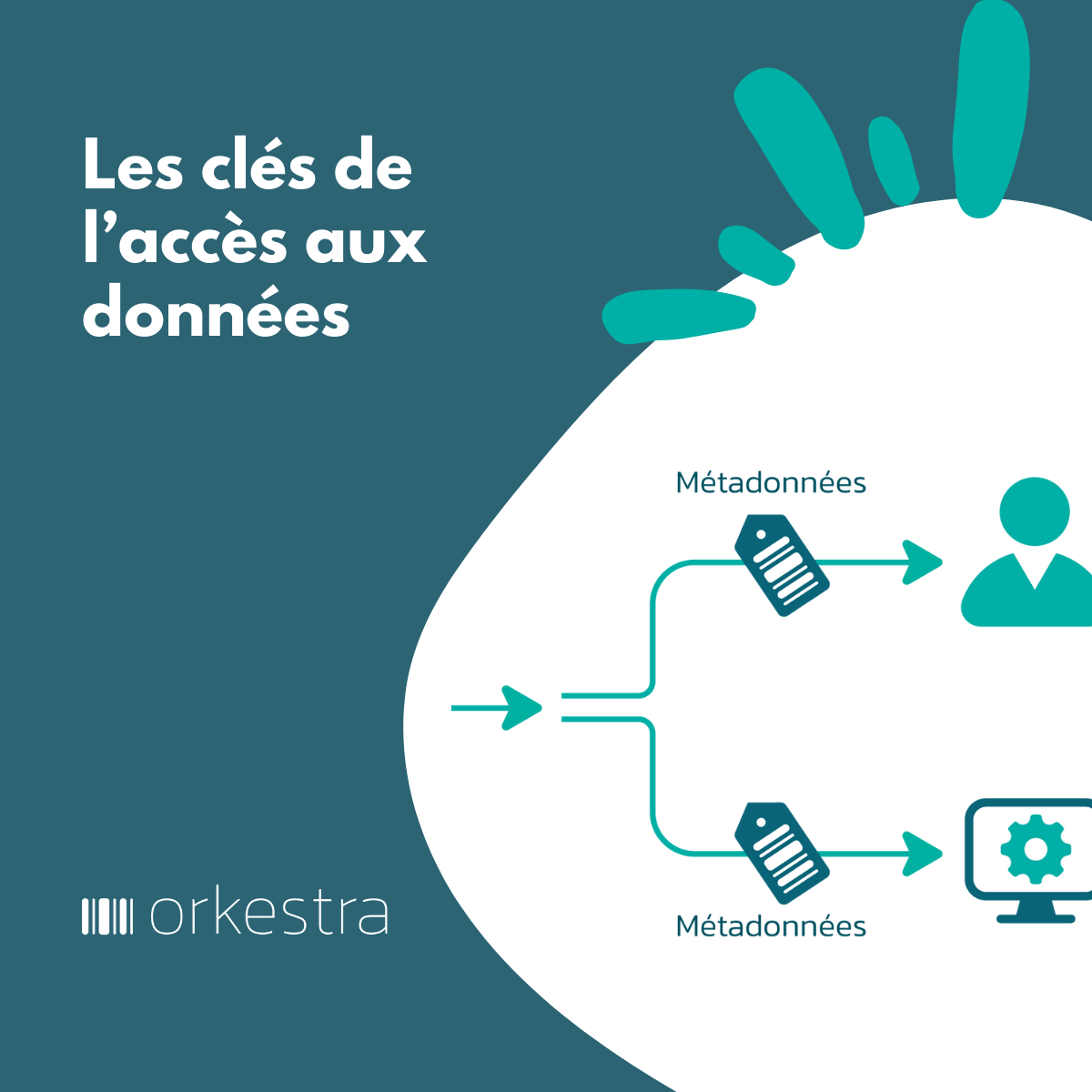
La promesse est d’étendre et de décentraliser dans un cadre fédéré, l’accès aux données en impliquant l’ensemble des métiers de l’organisation.
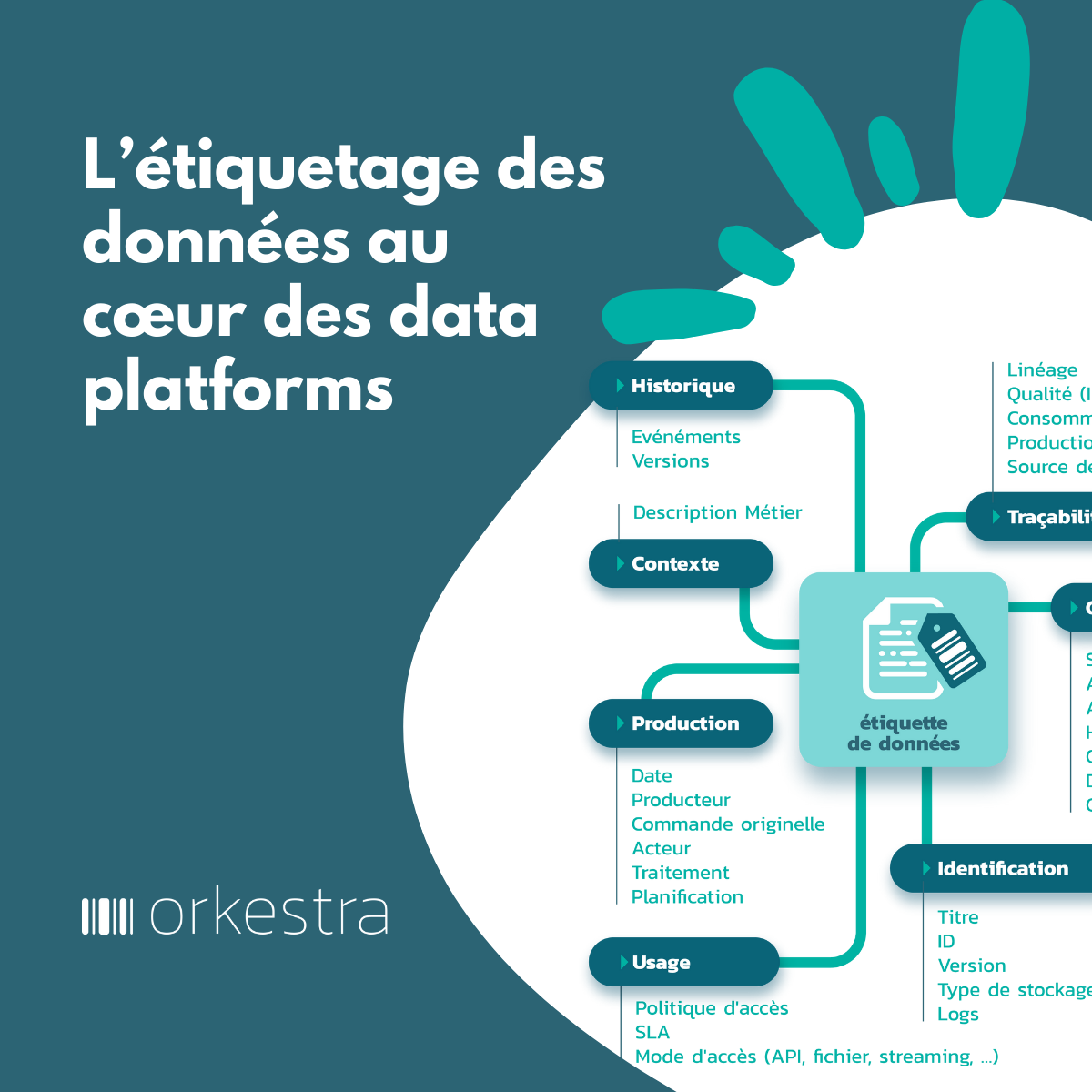
Cette vision demande un effort qui, sans un minimum d’automatisation (des étiquettes, des politiques, des data shop, de l’observabilité), sera souvent rédhibitoire. Cette automatisation est un des rôles attendus des Data Platforms.
Retrouvez toute l’étude sur les Data Platforms au travers de nos 2 guides :
- La dynamique des Data Platforms : qui pose un certain nombre de constats, d’éléments historiques, fondateurs et structurants.
- Le panorama des Data Platforms : qui explore la dynamique des data platforms au travers de la vision de plus d’une trentaine d’éditeurs du marché.