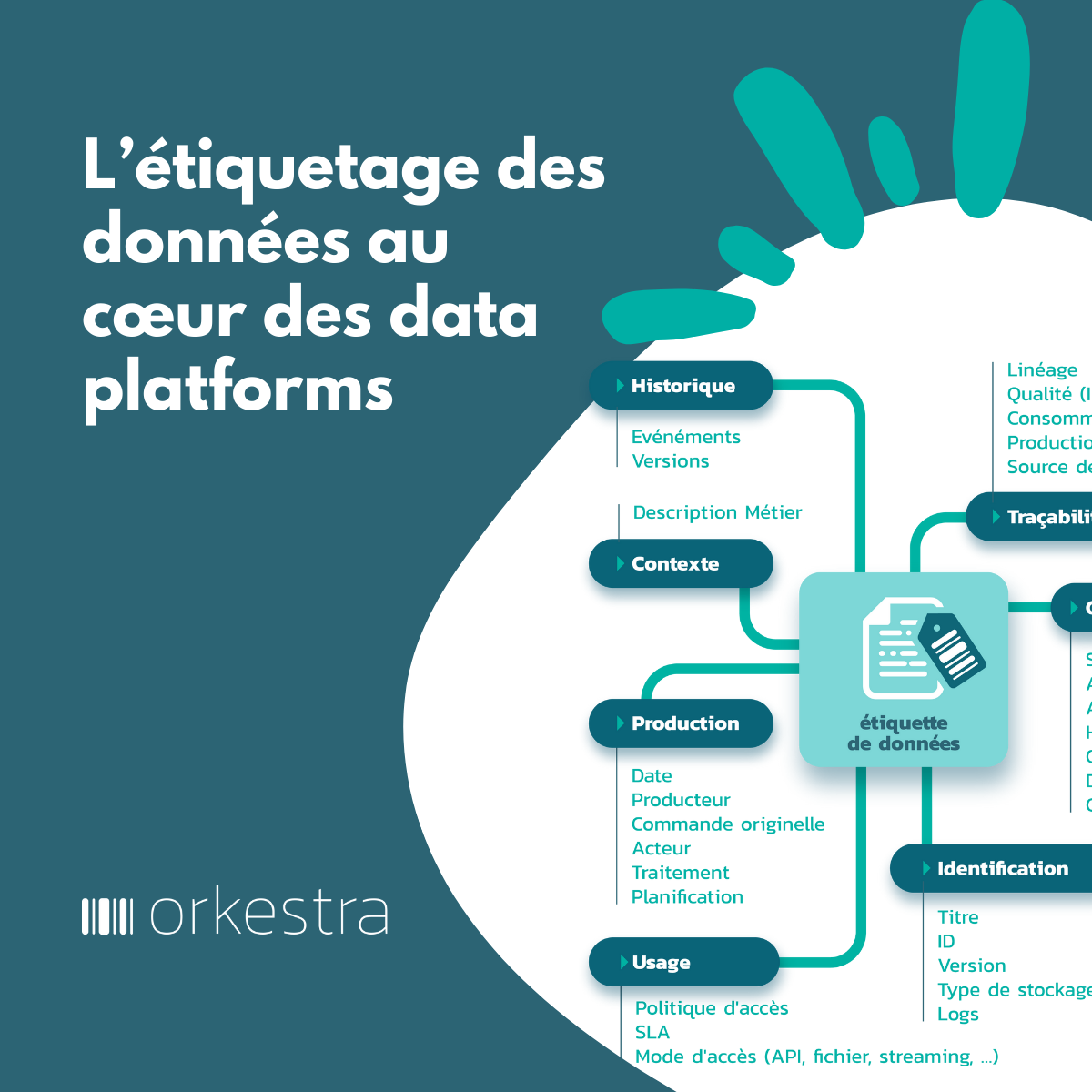
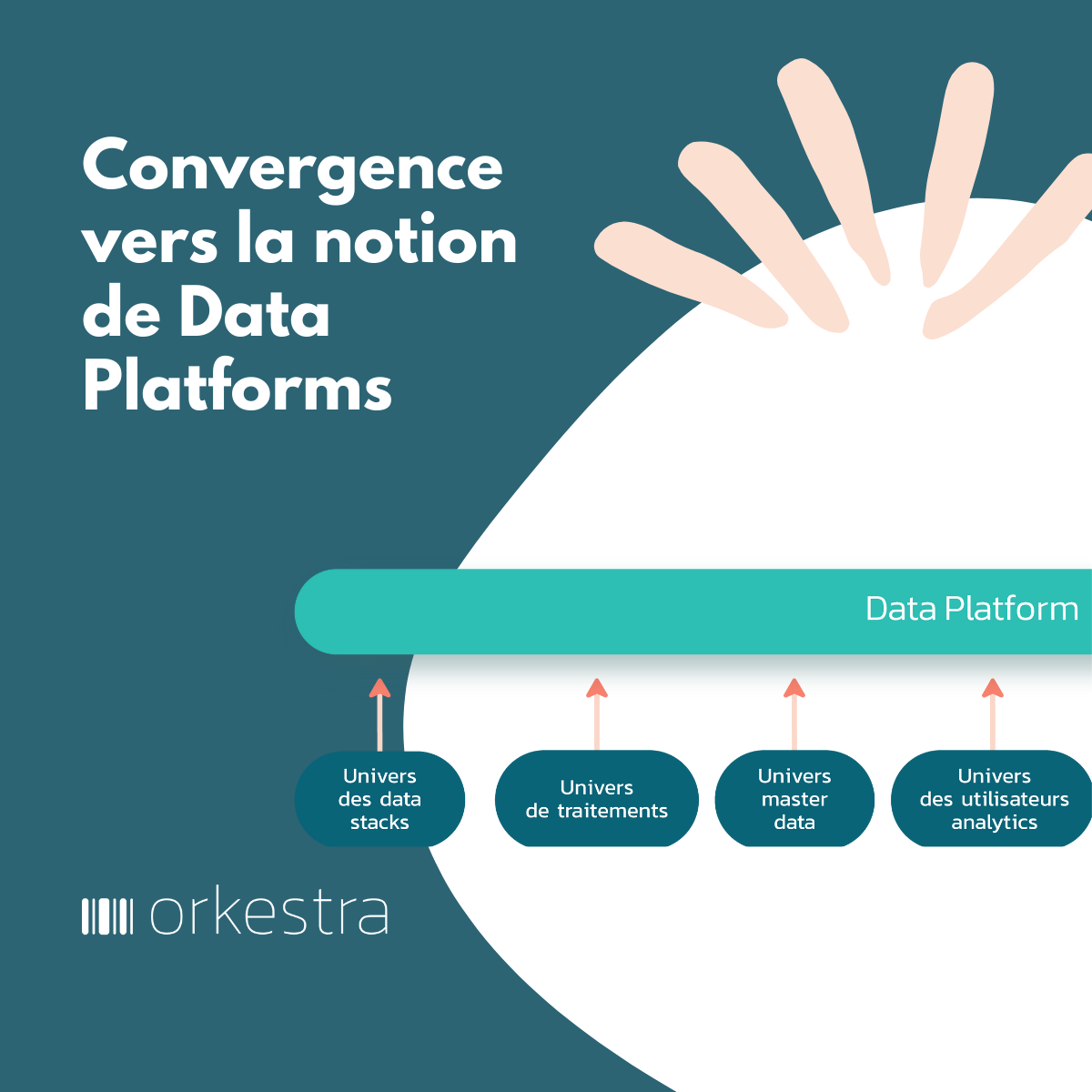
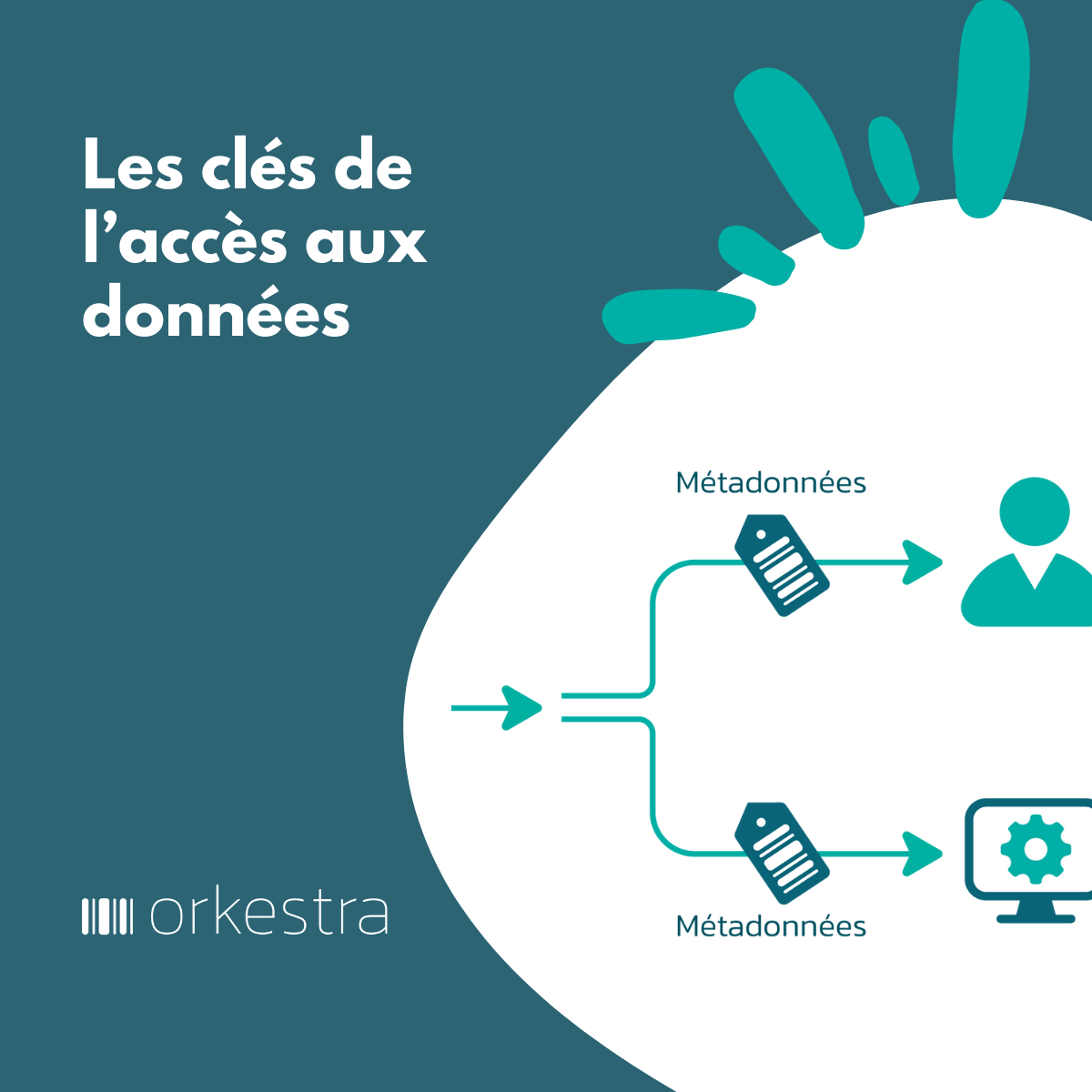
Lorsque les données sont enfouies dans des couches de stockage (SGBD, Datawarehouse, Data lake), il est nécessaire, pour y accéder, de faire appel à des moyens d’interrogation : par exemple via le langage SQL(1) majoritairement, ou via des outils de Business intelligence et le passage par une couche de programmation de type ETL (Extract Transform and Load). Le tout nécessite la connaissance des schémas de stockage des données.
Avec l’approche Produit, la philosophie d’accès change. Une fois le produit constitué, il va être disponible dans des espaces ou enseignes de données de type data shop, data marketplace ou collections de datasets, voire d’espaces open data.

Deux logiques s’y rencontrent, la logique de producteur de données et la logique de consommateur de données.
- Les producteurs de données vont dérouler tout le cycle amont de constitution des produits jusqu’à la mise en rayon. C’est eux qui vont faire l’effort de constituer les jeux de données, souvent à partir de sources existantes. Ils vont encapsuler l’effort d’accès aux données sources dans le produit. Pour cela, ils vont y attacher les étiquettes qui décrivent comment et dans quel environnement le produit a été constitué.
- Les consommateurs de données vont, eux, dérouler le cycle aval d’utilisation des données. Cycle qui commence par rechercher les données qui leur seront utiles dans les rayons des enseignes de données, et qui se poursuit par brancher les données dans leur environnement. C’est-à-dire, s’assurer que leur définition, format, contenu, qualité, statut est conforme ou peut s’adapter à leur environnement.
Souvent, le premier schéma d’utilisation des données fait que le producteur et le consommateur des données sont le même acteur. L’effort d’abstraction en produit peut alors sembler inutile, mais l’expérience montre qu’il est payant, et à double titre : dès lors que les données peuvent intéresser d’autres consommateurs, mais également pour le producteur lui-même s’il doit mettre ses données sous gouvernance (être capable de les expliquer, de gérer leur qualité, de s’assurer qu’elles respectent des cadres réglementaires, de contrôler les accès(2)).
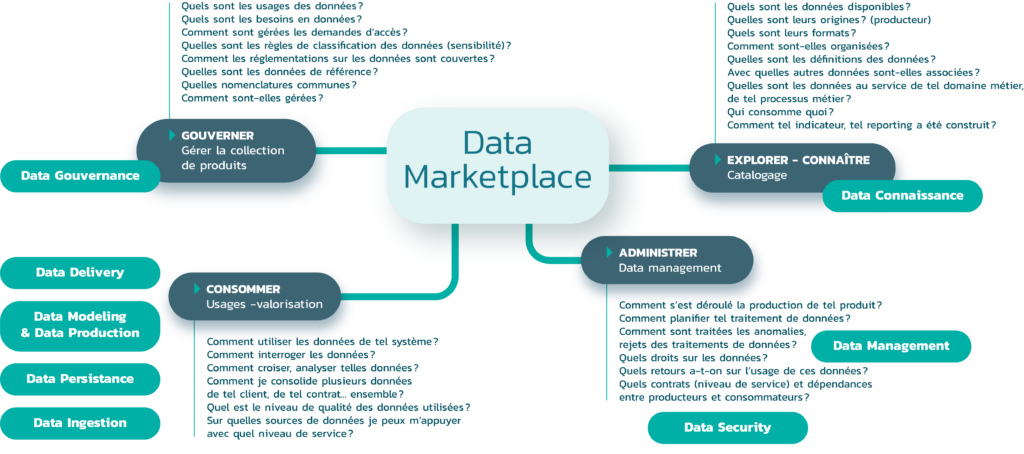
Dans les data platforms, la fonction de mise en rayon des données au travers de data marketplace devient clé. Elle doit être vue à la fois sous l’angle producteur de données et sous l’angle consommateurs de données : automatiser la mise en rayon, gérer l’étiquetage, faciliter la navigation, la recherche et l’exploration des données (les « feuilleter »), jusqu’à offrir des espaces de type bac à sable pour les tester ou encore de type « data clean room », c’est-à-dire de lieu de partage sécurisé, sans transport des données entre partenaires. Le tout accompagné par des fonctions collaboratives d’échanges entre producteurs (sachants) et consommateurs.
Cette fonction data marketplace offre une vision d’ensemble(3) (en un seul coup d’œil) des données. Elle permet de détecter : les données les plus demandées, réutilisées, les trous sur certaines données, les redondances (pourquoi tel jeu de données alors qu’il existe aussi celui-ci), les dépendances (entre jeux de données, entre producteurs et consommateurs de données). Elle permet d’exercer des tâches d’administration et de gouvernance (attribuer une sensibilité à certaines données, gérer les accès, contrôler la qualité).
Indispensables aux consommateurs de données, à l’administration et à la gouvernance des données, la fonction de data shop devient centrale dans l’évolution du marché des data platforms. Et cette fonction fait l’objet d’une bataille au sein de ce marché, bataille que nous avons dépeint dans le « Panorama des data platforms ».
1) SQL est le premier moyen d’interrogation. Certains éditeurs de data platform l’ont bien compris en faisant reposer leur solution sur des moteurs SQL optimisés. Avec l’arrivée des IA génératives, ces moteurs sont complétés par la possibilité d’interroger par prompt (en langage naturel) les données via la génération automatique des requêtes SQL.
2) La règle qui interdit l’accès direct – sans passer par une couche de médiation – à une source de données est systématique pour plusieurs raisons, découplage du stockage avec l’usage, mais aussi pour des raisons sécurité. La dimension produit joue ce rôle de médiation.
3) Contribution à l’observabilité des données (data observability).
Retrouvez toute l’étude sur les Data Platforms au travers de nos 2 guides :
- La dynamique des Data Platforms : qui pose un certain nombre de constats, d’éléments historiques, fondateurs et structurants.
- Le panorama des Data Platforms : qui explore la dynamique des data platforms au travers de la vision de plus d’une trentaine d’éditeurs du marché.