L’étiquetage des données, ou comment les métadonnées servent la connaissance et l’accès aux données.
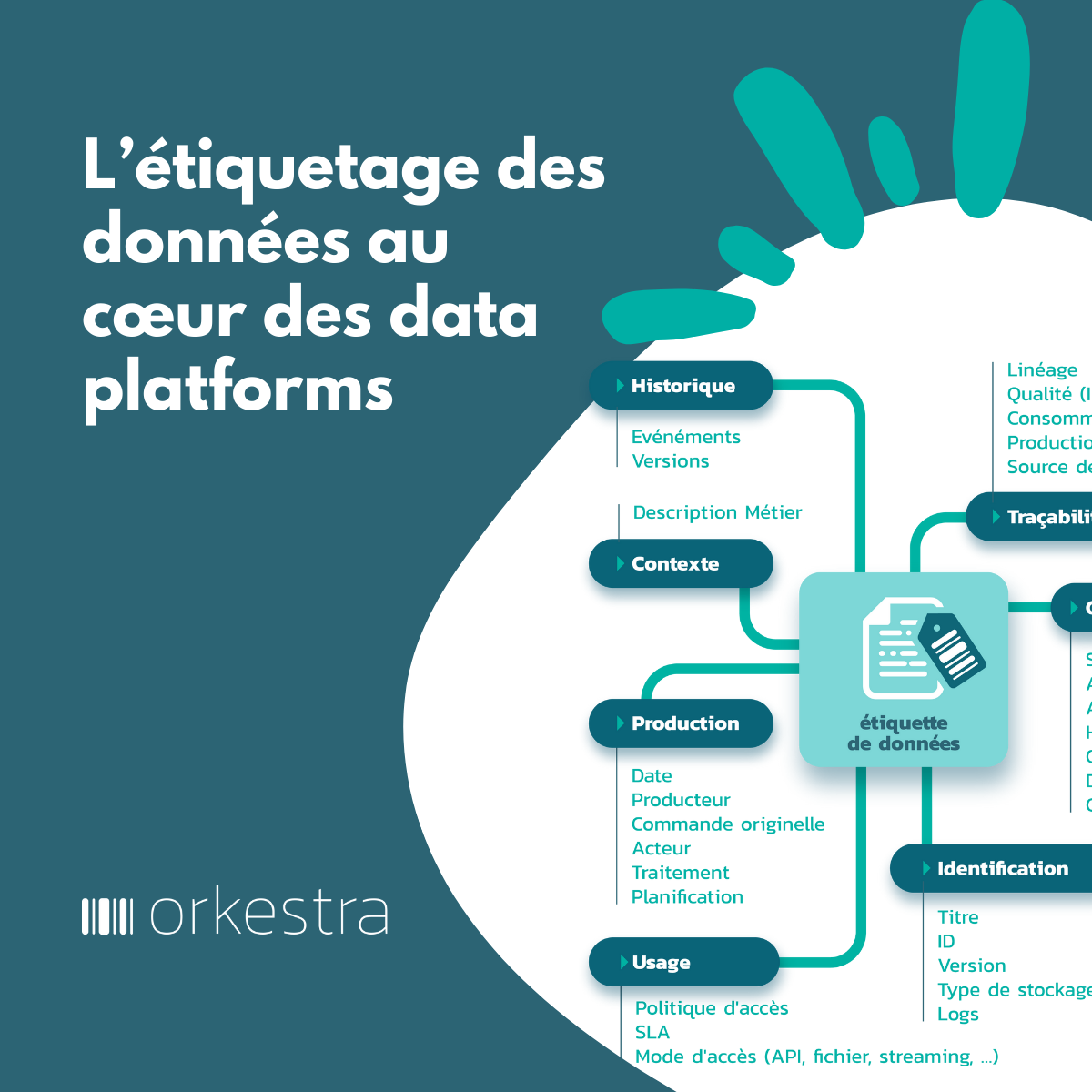
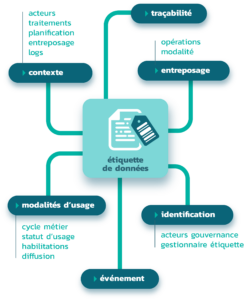
Les données sont devenues un objet de gestion qui comme pour un logiciel client, produit… vont faire appel à des données. Ces données sont appelées Métadonnées et se rassemblent au sein d’Étiquettes, on parle d’étiquetage des données.
Ces métadonnées sont essentielles pour l’ensemble des fonctions d’une data platform.
Au moment de l’ingestion, il est nécessaire de capter la source des données, leur description, la temporalité de l’ingestion, les anomalies. Un lien va être fait avec une couche sémantique, un modèle d’accueil des données (définition, entités de référence, nomenclatures utilisées). Des traitements vont être fait sur les données dont la structure sera tracée (lineage statique) ainsi que son fonctionnement (logs, lineage dynamique).
Des règles de sécurité vont être posées paramétrées en fonction de profils, de droits. Les fonctions de data management vont utiliser les métadonnées pour leur gestion et en même temps en générer de nouvelles (traces de mise en qualité, d’application de politiques). Les fonctions d’exposition vont faire appel aux métadonnées, pour permettre aux futurs consommateurs de comprendre les données. L’usage des données par ces derniers peut être enregistré comme métadonnées (et répondre ainsi à des questions du type : qui consomme quoi ?). Enfin via toutes ces métadonnées, la gouvernance peut disposer d’une vision d’ensemble (holistique – data observability), pour contrôler, orienter ses politiqu
Toutes ces métadonnées existent déjà pour partie dans les environnements de données existants (schémas de base de données, logs). Malheureusement elles sont dispersées, hétérogènes, difficilement accessibles et compréhensibles (logs) et partielles.
Certaines data platforms orientées data management essaient de les capter :
- soit via la récupération manuelle de description des données (catalogage, linéage),
- soit automatiquement par des connecteurs sur les environnements sources et de production
Mais l’expérience montre une grande difficulté de maintenir à jour à la main ces métadonnées. Et les récupérer automatiquement, c’est s’embarquer dans un projet d’intégration supplémentaire qui devient vite très lourd et coûteux.
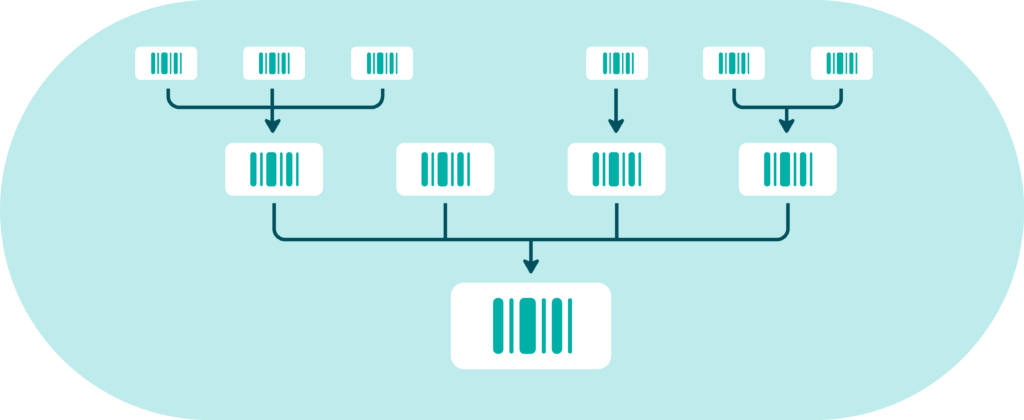
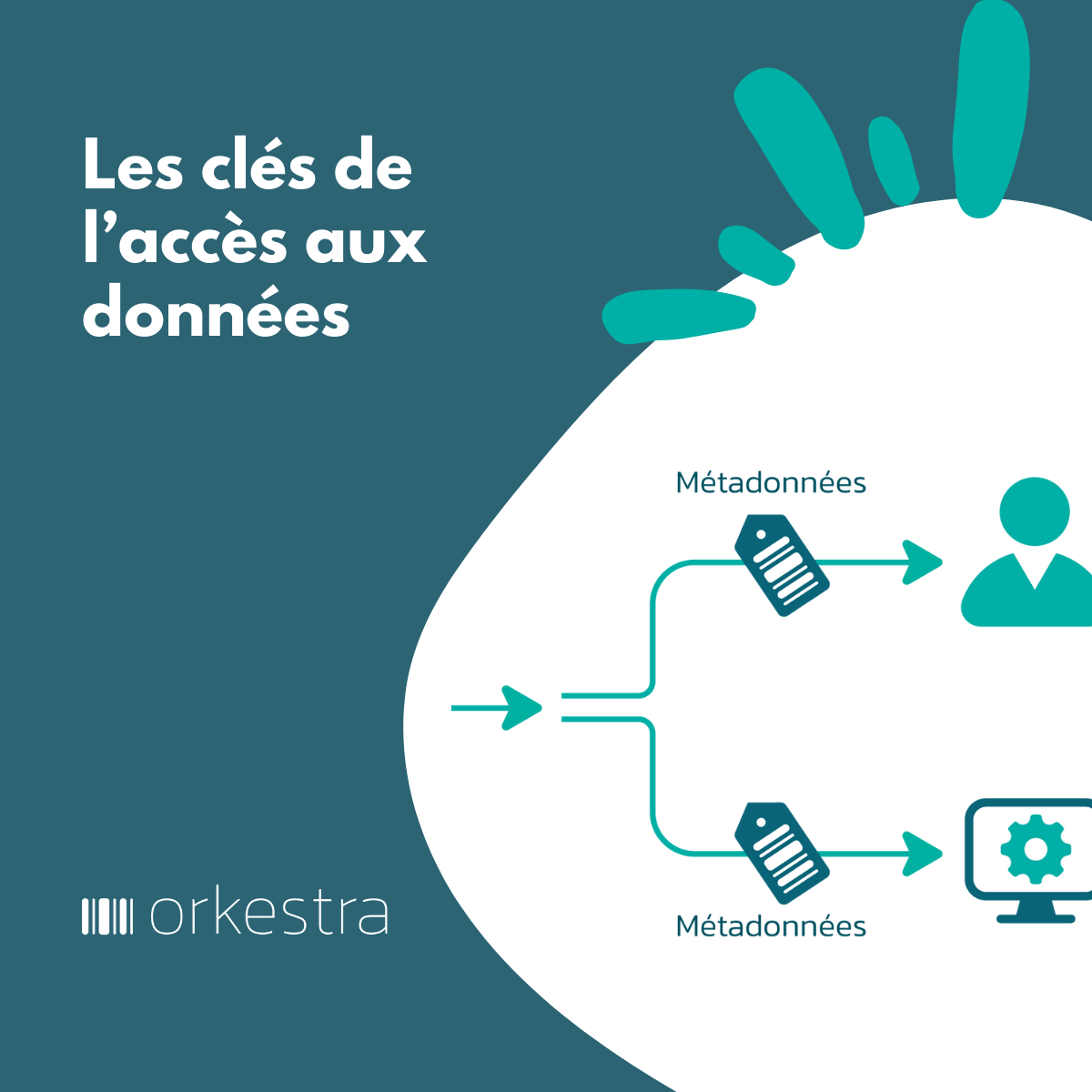
De façon optimale, il y a besoin de regrouper et de fédérer toutes ces métadonnées automatiquement au niveau des produits de données. C’est le rôle de étiquetage des données. L’étiquette attachée à un produit, va accueillir toutes les métadonnées. Et ces étiquettes pourront être utilisées par les différentes fonctions d’une data platform et exposées automatiquement dans des catalogues, des data shops.
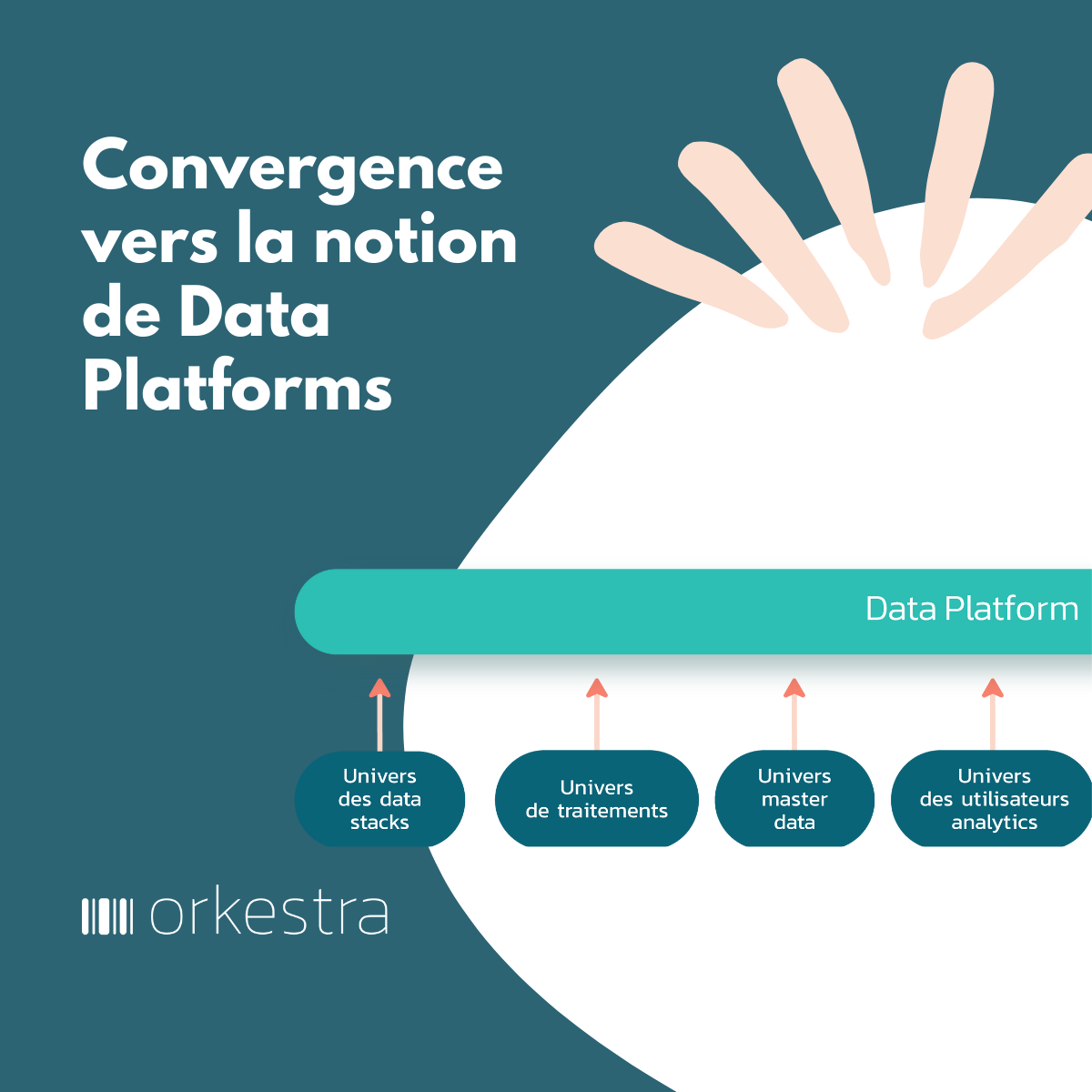
Les data platforms du marché, ont des niveaux de maturité différents sur ce point.
Certaines prennent en compte nativement cette idée d’étiquettes quand, pour d’autres, c’est malheureusement partiel, souvent limité à des métadonnées techniques non parlantes aux métiers, voire absent. Lorsque cette fonction d’étiquetage n’est pas native, les éditeurs de data platform essaient d’enrichir leur solution de cette capacité (par des rachats externes entre autres – exemple des fonctions de linéage).
Cette gestion d’étiquettes, va jouer un rôle clé dans l’idée de « self serve data platform ». Sans elle, impossible de répondre aux ambitions de cette capacité … sauf à retomber dans les travers du shadow data.
Retrouvez toute l’étude sur les Data Platforms au travers de nos 2 guides :
- La dynamique des Data Platforms : qui pose un certain nombre de constats, d’éléments historiques, fondateurs et structurants.
- Le panorama des Data Platforms : qui explore la dynamique des data platforms au travers de la vision de plus d’une trentaine d’éditeurs du marché.