D’un côté, les métiers ont de plus en plus d’attentes et de contraintes liées aux données. De l’autre, l’IT ne peut pas répondre à l’ensemble des besoins data d’une organisation.
Le tout s’inscrivant dans une dynamique d’agilité continue à l’échelle, d’innovation (« test and learn »), de reconfigurations, de développement de nouveaux marchés, d’incertitudes, de crises, où à chaque fois des données sont en jeu.
De fait, de plus en plus d’acteurs s’occupent de données. Le shadow data est présent partout. Et la démultiplication des forces data se fait naturellement mais souvent sans tous les moyens nécessaires.
L’idée de Self Serve Data Platform répond à ces enjeux :
- Démultiplier la capacité de l’organisation à opérer les données (lever les goulots d’étranglement de la centralisation, ouvrir les silos de données locaux), faciliter la coopération métier, acteurs data et IT,
- Être au plus près des acteurs métier qui portent les besoins, qui vivent les données au quotidien et peuvent assumer les responsabilités associées,
- Offrir la souplesse, l’autonomie du shadow data de façon encadrée : contrôlable, traçable, gouvernable, résilient.
Il y a quelques années est apparue l’idée de self BI, avec des solutions à la main des métiers pour créer leurs propres tableaux de bord et data visualisation.
L’idée de Self Serve Data Platform va beaucoup plus loin en offrant le moyen de gérer par les métiers ou par des acteurs data (en délégation), les données, sous forme de produits, en étant capable de suivre leur cycle de vie, au sein de processus métier, le tout dans le respect de règles de gouvernance.
Toute Data Platform doit être évaluée par rapport à cette capacité :
- Facilité de développement par des logiques low / no code,
- Capacité DataOps à la main des métiers tout au long du cycle de production puis de vie des données et produits de données,
- Self orchestration, supervision, monitoring des données et des traitements associés,
- Self consommation des données : data shop, espaces bacs à sable d’évaluation, fonctions support,
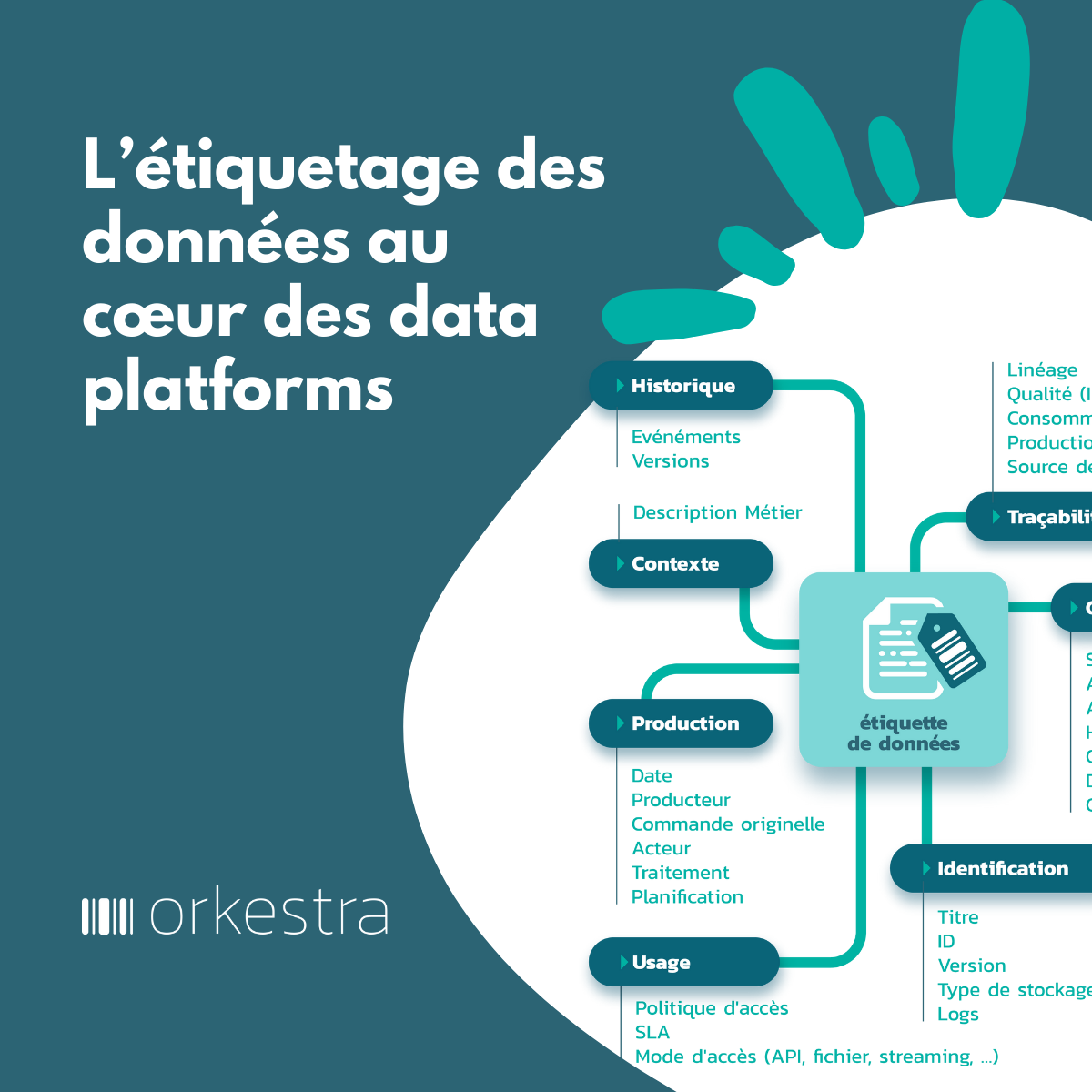
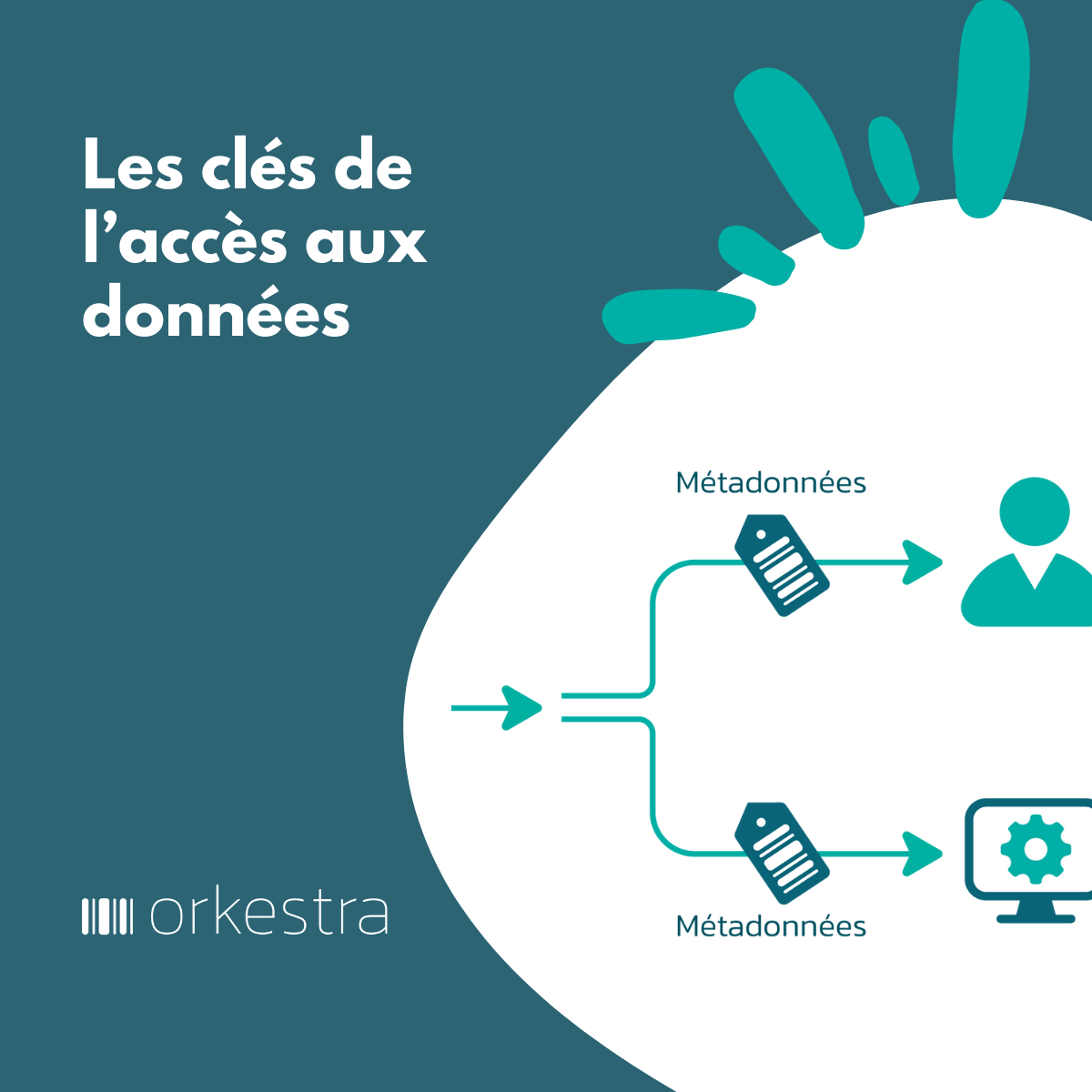
- Mise à disposition de fonctions de gouvernance (application des politiques de données) et de data management (exemple qualité des données, gestion des données de référence, sensibilité, gestion des accès) prêtes à l’emploi
L’IT n’y est plus vu comme un environnement et des moyens de développement, mais comme un facilitateur de cette logique self serve data. En apportant :
- Des connecteurs aux sources de données des systèmes existants prêts à l’emploi,
- Une infrastructure assurant les fonctions élémentaires : de persistance, de résilience (backup), de sécurité (accès et intégrité), de performance, de disponibilité… invoquées et paramétrées au travers de fonctions de data management,
- Et des principes techniques d’interopérabilité (formats, API standardisées de consommation des données).
Cette nouvelle répartition des rôles IT / self serve data Métier implique de nouvelles expertises côté métier, de nouvelles règles de coopération et de nouvelles responsabilités de part et d’autre. Elle va dans le sens où de plus en plus d’acteurs métier s’approprient directement le sujet des données et sont même formés à cela.
Les métiers vont découvrir de nouveaux gestes métier liées aux données, de nouvelles pratiques, de nouveaux risques, de nouvelles charges, qui vont nécessiter de nouvelles compétences et du temps (des moyens humains et financiers).
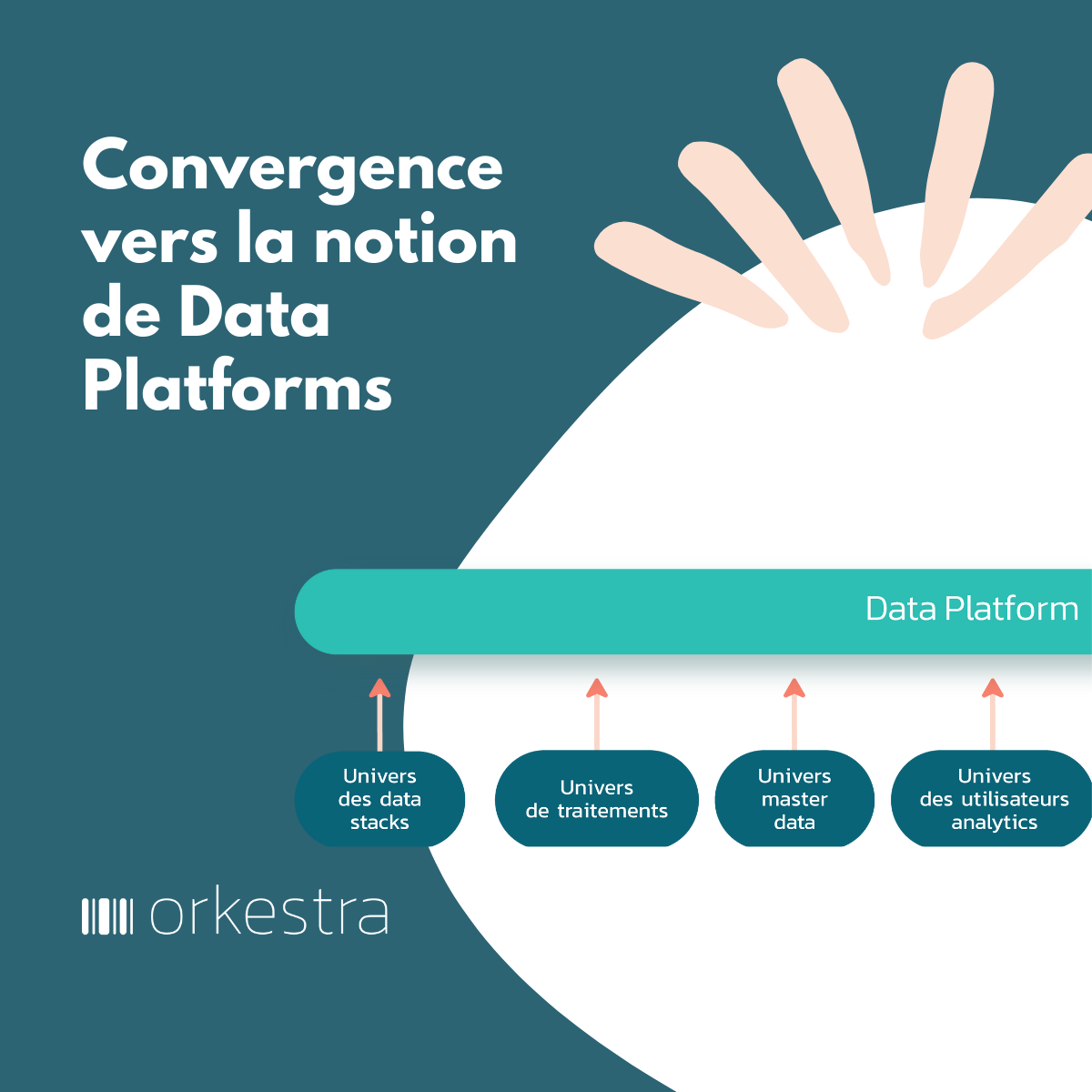
Par rapport à cette ambition de Self Serve Data Platform, le monde des data platform va se diviser en deux grands ensembles qui se recouvrent et se complètent pour partie : les data platforms orientées expérience métier et les data platform orientée expérience IT.
Retrouvez toute l’étude sur les Data Platforms au travers de nos 2 guides :
- La dynamique des Data Platforms : qui pose un certain nombre de constats, d’éléments historiques, fondateurs et structurants.
- Le panorama des Data Platforms : qui explore la dynamique des data platforms au travers de la vision de plus d’une trentaine d’éditeurs du marché.