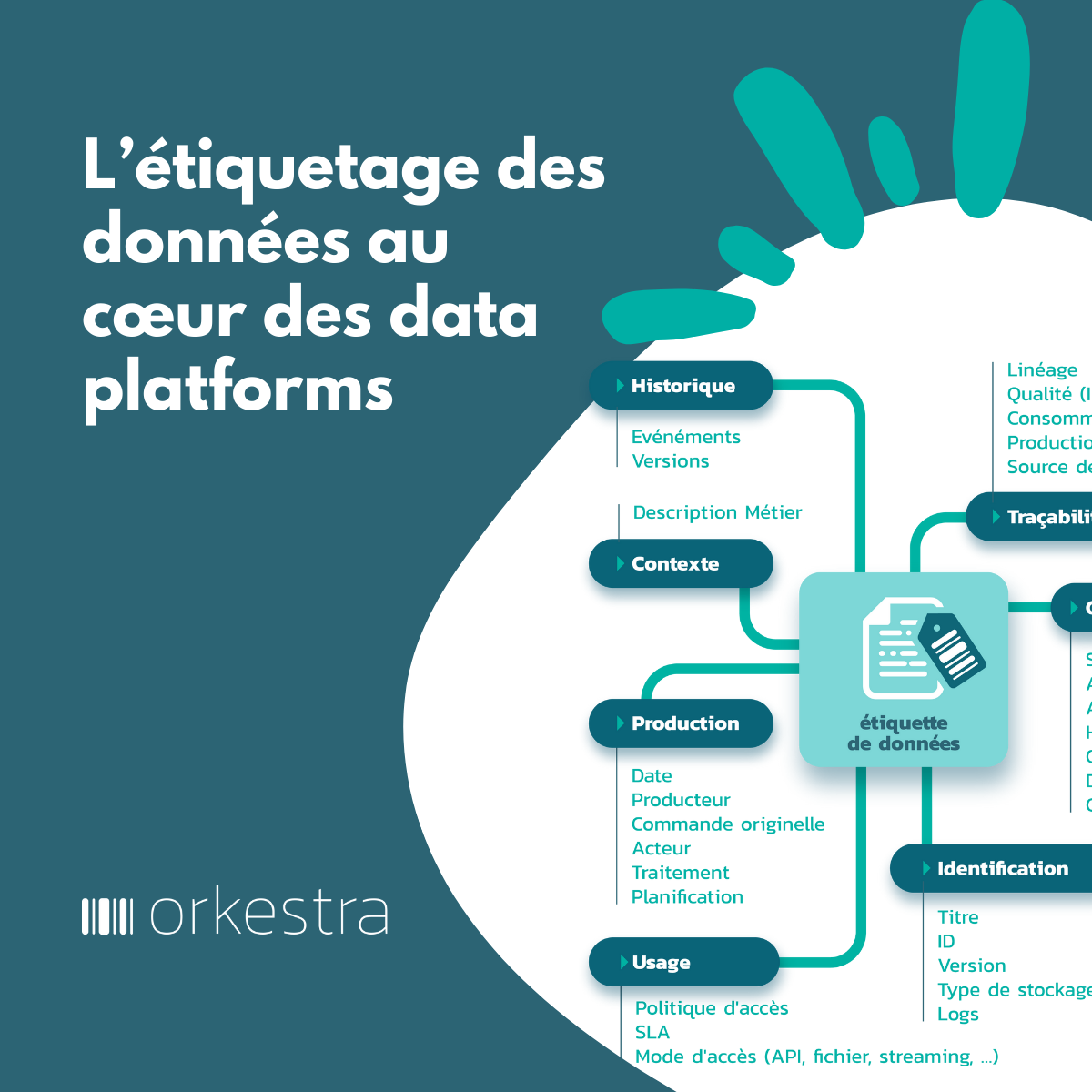
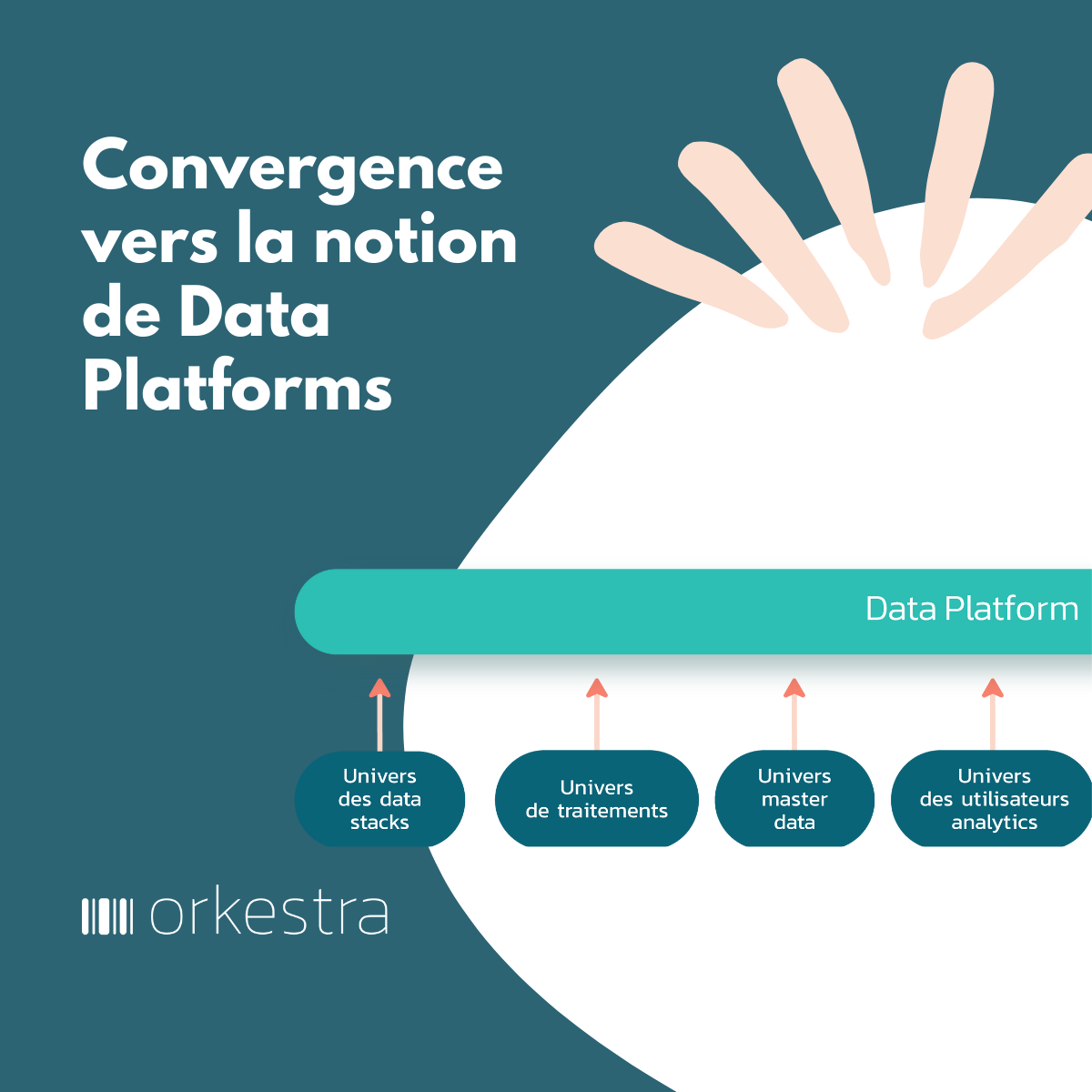
Le monde des données exacerbe l’effort d’intégration déjà difficile à traiter : intégrer la prolifération des données issues des projets de digitalisation, intégrer des sources existantes de données hétérogènes en silos, intégrer des fonctions de gestion des données (de data management), intégrer des jeux de données voire des data products (dans un cadre Data Mesh), intégrer des composants techniques support à la gestion de grands volumes de données, intégrer des flux de données jusqu’en temps réel, intégrer des solutions de sécurisation des données… et jusqu’à réintégrer le shadow data.
Le métier de data engineer est un des plus difficiles qu’il soit. Il doit mener à bien l’intégration de plates-formes support aux données, qui elles-mêmes devront être en mesure d’intégrer différentes natures et sources de données, différentes formes de consommation de données et cela dans un marché complexe où la course technologique est continue.
Une part importante des échecs historiques de construction de data platforms (big data, data lake, refonte de systèmes BI) est due à ne pas avoir su répondre au défi de l’intégration. L’intégration est le point dur de complexité, de coûts, de compétences difficiles à trouver (rareté), de risque, de délai de construction par rapport au time to demand et à une attente rapide de ROI (« Slow time to show ROI »), de pérennité dans le temps…
Face à cela, il existe un continuum d’intégration bien connu, entre partir de zéro et devoir tout intégrer (le best of breed) et faire appel à un progiciel déjà tout intégré.
Lorsqu’il va s’agir de sélectionner une data platform, il est important de connaître explicitement le curseur (l’effort) d’intégration à consentir

Le marché des data platforms va tourner autour de ce continuum, avec :
- Des multitudes de briques du marché ou open source (de persistance, d’ingestion, de traitement, de supervision, de data management, de sécurité…) à disposition et soit à intégrer dans une logique « mon best of breed », soit déjà pré-intégrée voire complètement intégrée par des éditeurs, disponibles dans le cloud,
- Des frameworks techniques et fonctionnels, où l’assemblage et l’intégration sont déjà réalisés à partir d’une suite de composants prédéfinis et qui, dans la logique de framework, peuvent être interchangés (plug and play) en fonction d’un contexte client (par exemple en tenant compte d’une solution data – un ETL du marché – référencée par le client et que le framework sait prendre en compte – présent dans son catalogue de solutions intégrables),
- Et enfin des plates-formes « progiciel » toutes intégrées, prêtes à l’emploi, embarquant soit des composants propriétaires (par exemple un ETL), soit des composants open source.
Retrouvez toute l’étude sur les Data Platforms au travers de nos 2 guides :
- La dynamique des Data Platforms : qui pose un certain nombre de constats, d’éléments historiques, fondateurs et structurants.
- Le panorama des Data Platforms : qui explore la dynamique des data platforms au travers de la vision de plus d’une trentaine d’éditeurs du marché.